Assistant Professor
University of Western Macedonia, Department of Communication and Digital Media
I am an Assistant Professor at the University of Western Macedonia at the Department of Communication and Digital Media, Kastoria, Greece. I received my Ph.D. from the Department of Computer Science & Engineering, University of Ioannina, Greece, and my M.Sc. and B.Sc. in Computer Science from the same institution. For the Academic year 2018-2019, I was an Adjunct Lecturer at the Department of Computer Science & Engineering, University of Ioannina. In the past, I spent two years at the University of Houston, TX, USA where I worked as a Postdoctoral Fellow at Computational Biomedicine Lab and at the Texas Institute for Measurement, Evaluation & Statistics.
My research covers a wide range of topics such as Virtual and Augmented Reality, Computer Vision, Image and Video Processing, Image Analysis, Machine Learning, and Pattern Recognition with applications also to Medical Image Analysis and Biometrics.
University of Western Macedonia, Department of Communication and Digital Media
University of Ioannina, Department of Computer Science & Engineering
University of Ioannina, Department of Computer Science & Engineering
University of Houston, Computational Biomedicine Lab
Ph.D. in Computer Science
University of Ioannina
Department of Computer Science and Engineering
Master in Computer Science
University of Ioannina
Department of Computer Science
Bachelor in Computer Science
University of Ioannina
Department of Computer Science

Education is an admirable thing. But it is well to remember from time to time that nothing that is worth knowing can be taught.
Instructor For more information see the course web page here.
Instructor For more information see the course web page here.
Instructor For more information see the course web page here.
Instructor - Co-teaching For more information see the course web page here.
Instructor - Co-teaching For more information see the course web page here.
Instructor - Co-teaching For more information see the course web page here.
Instructor
Instructor
Instructor
Instructor
Instructor
Instructor
Instructor - Co-teaching
Instructor
Instructor
© Copyright Notice: This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. These works may not be reposted without the explicit permission of the copyright holder. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright and/or copyright holders. All statements of fact, opinion or conclusions contained herein are those of the authors and should not be construed as representing the official views or policies of the sponsors. In most cases, these works may not be reposted without the explicit permission of the copyright holders. Please contact authors for further details.
Immersive and digital technologies have been gaining increasing recognition as effective tools that can help to enhance tourism experience and promote destination through interactive digital content. In the case of rehabilitated mining areas, these innovative technologies could contribute towards the transition of rehabilitated mining areas into sustainable tourism destinations. Through immersive experiences, potential visitors can explore rehabilitated mining sites, particularly when these areas are redeveloped into cultural, historical, or ecological attractions. This paper studies the contribution of immersive and digital technologies in promoting and elevating tourism experiences in the rehabilitated mining areas of Western Macedonia, Greece. Data was collected through an online questionnaire completed by 100 respondents in September 2025. Before completing the survey, the respondents had watched a short video presenting four proposed rehabilitation scenarios for the mining areas: the development of an artificial lake network, a mining history center, a science park and a lignite vineyard. The questionnaire contained questions evaluating the perception of various innovative technologies, including virtual and augmented reality, interactive applications, 360° virtual reality videos, 3D digital models, gamification, social media storytelling and sustainable technologies. The collected data was statistically analyzed using IBM SPSS Statistics. Overall, respondents expressed a relatively positive attitude on the adoption of immersive and digital technologies at the rehabilitated mining areas. While recognizing the potential of immersive and digital technologies for enhancing tourism experience, they were more doubtful about replacing a physical visit with an immersive experience. Thus, the use of immersive technologies seems to be more suitable as additional tools. Among the presented digital technologies, the 3D digital representation, social media storytelling and sustainable technologies gained the highest scores. In conclusion, this research highlights the necessity of combining immersive technologies with sustainable development principles in order to transform rehabilitated mining areas to competitive sustainable tourism destinations.
@inproceedings{Koliouska_and_Vrigkas_2026,
author = {Christiana Koliouska and Michalis Vrigkas},
title = {On enhancing tourism experience in rehabilitated mining areas using immersive and digital technologies},
booktitle = {Proc. 13th International Conference of the International Association of Cultural and Digital Tourism},
address = {Lesbos, Greese},
pages = {1--11},
month = {September},
year = {2026}
}
Reliable identity preservation is essential in retail multi-object tracking because an identity switch may assign dwell time, shelf interactions, or demographic statistics to the wrong consumer trajectory. This challenge is amplified in crowded indoor scenes, where occlusions and appearance ambiguity weaken conventional association cues. This work presents a demographic-aware multi-object tracking framework for retail environments that exploits spatial, motion-based, appearance-based, and demographic cues within a modular tracking-by-detection pipeline. The proposed approach integrates IoU-based spatial association, LSTM-based motion forecasting, ReID appearance embeddings, and apparent demographic information derived from age-group and gender predictions into a common association cost. The core assumption is that demographic attributes should remain consistent across neighboring frames for the same tracked individual; therefore, demographic agreement can serve as a weak semantic cue during detection-to-tracklet association. Unlike conventional pipelines that treat multi-object tracking and demographic estimation as independent stages, the proposed method reuses the outputs of an existing Inception-based apparent demographic classifier to support identity preservation, without introducing a new demographic estimation model or requiring end-to-end retraining. The framework is evaluated on RGB retail tracking sequences from the Consumers dataset under both raw and privacy-aware anonymized settings. The proposed method achieves 84.8% MOTA and 87.8% IDF1 on raw data and 80.0% MOTA and 85.3% IDF1 under anonymization, improving the strongest evaluated baseline by 0.4 and 0.6 percentage points and by 1.0 and 1.3 percentage points, respectively, while preserving the same low ID-switch counts. Although incremental in absolute terms, these gains are consistent across both evaluation settings and are obtained over a strong baseline in challenging indoor retail sequences. The results indicate that even a lightweight demographic-consistency cue can provide measurable complementary information for improving consumer trajectory stability.
@article{Electronics_2026,
author = {Iason-Ioannis Panagos and Angelos P. Giotis and Marina E. Plissiti and Vasiliki Stamati and George Gartzonikas and Michalis Vrigkas and Christophoros Nikou},
title = {Demographic-aware multi-object tracking for retail environments via temporal consistency and joint association},
journal = {Electronics},
volume = {15},
number = {14},
pages = {1--20},
article-number = {3089},
month = {July},
year = {2026},
ISSN = {2079-9292},
doi = {10.3390/electronics15143089}
}
Parkinson’s disease (PD) presents significant diagnostic challenges due to the complexity of neuroanatomical changes and the subtle progression of motor and cognitive symptoms. Traditional deep learning approaches, while effective, often fail to capture the complex, non-Euclidean structural and functional relationships inherent in brain connectomes. This review systematically examines the emergence of graph neural networks (GNNs) as a transformative tool for PD analysis using magnetic resonance imaging (MRI). We evaluate state-of-the-art architectures, including graph convolutional networks (GCNs) and graph attention networks (GATs), focusing on their ability to model brain networks from multi-modal data. By synthesizing findings from recent high-impact studies, we highlight the superior performance of GNNs in differential diagnosis, stage prediction, and identifying biomarkers for deep brain stimulation. Furthermore, we discuss the integration of explainable AI (XAI) within graph frameworks to enhance clinical interpretability. This review outlines current limitations and proposes future research directions to accelerate the clinical adoption of graph-based diagnostic systems.
@inproceedings{VStergiou_etal26,
author = {Vasileios Stergiou and Angelos Giotis and Michalis Vrigkas and Loukas Astakas and Spyridon Konitsiotis and Christophoros Nikou},
title = {Graph neural networks for neuroimaging-based Parkinson’s disease analysis: A comprehensive review},
booktitle = {Proc. First DeepTech Connect International Conference},
address = {Ioannina, Greese},
pages = {1--4},
month = {April},
year = {2026}
}
In the ever-evolving world of gaming, controller-based input is quickly becoming obsolete. Various applications, including virtual reality (VR) and augmented reality (AR) games, have used motion- and gesture-controlled video game consoles. The current state of the art relies on depth images of the hand that do not utilize color information from the RGB spectrum. In this work, we focus on the development of an interactive VR game that utilizes hand pose recognition from the RGB domain to increase user experience but also simplify the functionality of the game. To address this challenge, a 3D multi-user VR game themed around a “tennis match” was developed using the Unity engine. We also investigate whether we can estimate the coordinates of colored objects connected to the hand movement of the players and track human gestures to navigate through the game functions in real time using an RGB camera. Statistical analysis showed that the user experience increased concerning engagement and satisfaction using a more natural form of control that allows players to focus on the excitement of the game without worrying about button presses or joystick movements. Such hand pose recognition systems can be implemented to replace the traditional controller-based entry systems used today.
@article{Gkoutzios_Vrigkas_CAWV_2025,
author = {Stefanos Gkoutzios and Michalis Vrigkas},
title = {A multi-user virtual reality game based on gesture recognition from RGB information},
journal = {Computer Animation and Virtual Worlds},
volume = {36},
number = {5},
pages = {e70063},
article-ID = {100288076},
month = {September},
year = {2025},
doi = {10.1002/cav.70063}
}
This paper presents an augmented reality (AR) mobile application developed for Android devices, which brings five bust sculptures of historical personalities of the city of Komotini, Greece, to ‘life’ using the Unity engine. These busts narrate their achievements in two languages, Greek and English, to educate visitors on historical and cultural heritage and provide a comprehensive glimpse into the area’s past using 3D models, textures, and animations tailored to the educational content. Based on the users’ location, the application provides an interactive educational experience, allowing the users to explore the history and characteristics of the busts in an innovative way. The users may interact with the busts using markerless AR, discover information and historical facts about them, and stimulate their understanding of the busts’ significance in the context of local history and culture. Interactive elements, such as videos and 3D animations, are incorporated to enrich the learning experience. A location-based knowledge quiz game was also developed for this purpose. The application was evaluated by statistical analysis to measure the effect of using the application on the involvement of users in the educational process and to study the users’ satisfaction and experience. This approach revealed that the proposed AR app is effective in providing educational content, promotes active user participation, and provides a high level of user satisfaction.
@article{VirtualWorlds_2025,
author = {Christos Mourelatos and Michalis Vrigkas},
title = {Integrating augmented reality and geolocation for outdoor interactive educational experiences},
journal = {Virtual Worlds},
volume = {4},
number = {2},
pages = {1--23},
article-number = {18},
month = {May},
year = {2025},
doi = {10.3390/virtualworlds4020018}
}
This paper provides an overview of the perceptions of the Greek citizens on the positive effects of VR tool for the promotion of the rehabilitated mines in Western Macedonia. A questionnaire was delivered to a sample of 100 participants (both male and female of all ages) in September 2024. The questionnaire consisted of 26 closed questions about demographic data, the impacts of mining activities on the natural environment, the recommendations for mine rehabilitation, the use of new technologies to promote rehabilitated mines. The questionnaire included a short video that presented the recommendations for mine rehabilitation in Western Macedonia: an artificial lakes network, a mining history centre, a science park and a lignite vineyard. The collected data were analyzed using SPSS in order to apply descriptive, correlation and factor analysis. By this way, the activities that Greek residents prefer to do in rehabilitated mines are clarified and suggestions regarding the most efficient VR tool for the promotion of each rehabilitated mine is made.
@inproceedings{Koliouska_and_Vrigkas_2024,
author = {C. Koliouska and Michalis Vrigkas},
title = {Virtual Reality as a tool to promote tourism in rehabilitated mines},
booktitle = {Proc. 9th Mediterranean Tourism Knowledge Exchange and Policy Forum, "ARTS – Amidst Rapid Transformational Shifts", Mediterranean Tourism Foundation},
address = {Malta},
pages = {34--37},
month = {November},
year = {2024}
}
The accurate segmentation of cells in cervical images is crucial for the recognition of pathological situations and the estimation of their severity. In this work, we investigate the segmentation of both the nucleus and the cytoplasm of each cell based on two Generative Adversarial Networks (GANs). First, we detect the location of the nucleus with the extraction of the nucleus boundaries in each cell, which is obtained by the training of the Nucleus-GAN. The segmented nucleus area serves as a guide factor for the definition of the cell boundary, and it is used as input in the Cell-GAN, for the segmentation of the cell boundaries. As it is verified by the experimental results, the proposed method is efficient and leads to accurate nucleus and cell boundaries, presenting high performance.
@inproceedings{Lavntaniti_etal_ISBI2024,
author = {Kostantsa Lavntaniti and Marina E. Plissiti and Michalis Vrigkas and Christophoros Nikou},
title = {Accurate cell segmentation based on generative adversarial networks and nuclei guide factors},
booktitle = {Proc. 21st IEEE International Symposium on Biomedical Imaging (ISBI)},
address = {Athens, Greese},
pages = {1--4},
month = {May},
year = {2024},
doi = {10.1109/ISBI56570.2024.10635368}
}
Rapid growth in algorithms and computing power over recent years has spurred the emergence of machine learning and image processing techniques as new tools, which are rapidly entering every aspect of our life, from intelligent personal assistance such as Siri, Alexa, and Google Home to self-driving cars. The medical community has begun taking advantage of these new possibilities to create new predictive models and improve existing models. For example, novel methods applying machine learning and image processing/analysis methods that are robust and theoretically sound to solve the learning task efficiently and intuitively have become widespread across different facets of biomedical imaging for identifying complex patterns. Likewise, advances in biomedical imaging may lead to new technologies for developing predictive models for all diseases and guide the decision of who should receive preventive therapy.
The aim of this paper is to present an approach that utilizes several mixed reality technologies for touristic promotion and education. More specifically, mixed reality applications and games were created to promote the mountainous areas of Western Macedonia, Greece, and to educate visitors on various aspects of these destinations, such as their history and cultural heritage. Location-based augmented reality (AR) games were designed to guide the users to visit and explore the destinations, get informed, gather points and prizes by accomplishing specific tasks, and meet virtual characters that tell stories. Furthermore, an immersive lab was established to inform visitors about the region of interest through mixed reality content designed for entertainment and education. The lab visitors can experience content and games through virtual reality (VR) and augmented reality (AR) wearable devices. Likewise, 3D content can be viewed through special stereoscopic monitors. An evaluation of the lab experience was performed with a sample of 82 visitors who positively evaluated features of the immersive experience such as the level of satisfaction, immersion, educational usefulness, the intention to visit the mountainous destinations of Western Macedonia, intention to revisit the lab, and intention to recommend the experience to others.
@article{Computers_23,
author = {Alexandros Kleftodimos and Athanasios Evagelou and Stefanos Gkoutzios and Maria Matsiola and Michalis Vrigkas and Anastasia Yannacopoulou and Amalia Triantafillidou and Georgios Lappas},
title = {Creating location-based augmented reality games and immersive experiences for touristic destination marketing and education},
journal = {Computers},
volume = {12},
number = {11},
pages = {1--34},
article-number = {227},
month = {November},
year = {2023},
doi = {10.3390/computers12110227}
}
The work aims to design and implement a 3D interactive and addictive object avoidance game using the Unity platform. The implementation of the immersive virtual reality application uses any smart mobile device as an input and output device, utilizing its accelerometer and compass to record the orientation and rotation data of the device in 3D space and capture the digital environment stereoscopically on the device screen. A comparative study between a virtual reality and a desktop real-time 3D game is performed to analyze the various attributes of the game and determine which medium is most effective.
@inproceedings{Vrigkas_et_al_3DCVP_ICIP23,
author = {Michalis Vrigkas and Christophoros Nikou},
title = {A virtual reality 3D game: A comparison between an immersive virtual reality application and a desktop experience},
booktitle = {Proc. IEEE International Conference on Image Processing Challenges and Workshops (ICIPCW)},
address = {Kuala Lumpur, Malaysia},
pages = {3725--3729},
month = {October},
year = {2023},
doi = {doi: 10.1109/ICIPC59416.2023.10328382}
}
High-resolution images play an essential role in the performance of image analysis and pattern recognition methods. However, the expensive setup required to generate them and the inherent limitations of the sensors in optics manufacturing technology leads to the restricted availability of these images. In this work, we exploit the information retrieved in feature maps using the notable VGG networks and apply a transformer network to address spatial rigid affine transformation invariances, such as translation, scaling, and rotation. To evaluate and compare the performance of the model, three publicly available datasets were used. The model achieved very gratifying and accurate performance in terms of image PSNR and SSIM metrics against the baseline method.
@inproceedings{Rempakos_et_al_ICIAP23,
author = {Pantelis Rempakos and Michalis Vrigkas and Marina E. Plissiti and Christophoros Nikou},
title = {Spatial Transformer Generative Adversarial Network for Image Super-Resolution},
booktitle = {Proc. 22nd International Conference on Image Analysis and Processing},
address = {Udine, Italy},
pages = {399--411},
month = {September},
year = {2023},
doi = {10.1007/978-3-031-43148-7_34}
}
In this work, we solve the problem of motion representation in videos, according to local transformations applied to specific keypoints extracted from static the images. First, we compute the coordinates of the keypoints of the body or face through a pre-trained model, and then we introduce a convolutional neural network to estimate a dense motion field through optical flow. Next, we train a generative adversarial network that exploits the previous information to generate new images that resemble as much as possible the target frames. To reduce trembling and extract smooth movements, our model incorporates a low-pass spatio-temporal Gaussian filter. Results indicate that our method provides high performance and the movement of objects is accurate and robust.
@inproceedings{MVrigkas_etal_ICASSP_23,
author = {Michalis Vrigkas and Virginia Tagka and Marina E. Plissiti and Christophoros Nikou},
title = {Composition of motion from video animation through learning local transformations},
booktitle = {Proc. IEEE International Conference on Acoustics, Speech and Signal Processing},
address = {Rhodes Island, Greece},
pages = {1--5},
month = {June},
year = {2023}
}
Augmented reality (AR) applications are regarded as effective experiential marketing practices that can help companies promote their products/services in an interactive manner and deliver exceptional consumer experiences. The purpose of the present study is to evaluate a wine-label AR mobile application by examining its impact on consumer experience dimensions, satisfaction, and re-usage intentions towards the application, as well as attitude and purchase intentions towards the wine product. Moreover, to test the effect of product-consumption related factors (consumption frequency, amount of spending, wine expertise, and attention to wine labels) and technology-related factors (consumers’ familiarity with smartphone applications, number of AR applications used in smartphone, and extent of information search for wine-related information through smartphones) on the experiential dimensions of entertainment, flow, escapism, and education. Towards this end, a wine AR label application was developed and evaluated using a quantitative survey. In total, 306 respondents answered a self-administered questionnaire after interacting with the application. Results indicate that the AR application induced the entertainment and educational dimensions of consumer experience. The AR experience was also able to increase respondents’ satisfaction with the application and in turn help them form positive attitudes and purchase intentions for the wine. Moreover, the present study revealed that respondents’ expertise for wine, attention to wine label, familiarity with smartphone applications, and information search for wine-related information through smartphones are important factors that have an impact on the experience lived by consumers when using the AR label application.
@inproceedings{ICDEc23,
author = {A. Triantafillidou and M. Vrigkas and A. Kleftodimos and A. Yannacopoulou and M. Matsiola and S. Gkoutzios and G. Lappas},
title = {Consumer experience and augmented reality wine label application},
booktitle = {Proc. 8th International Conference on Digital Economy},
address = {Braga, Portugal},
pages = {263--273},
month = {May},
year = {2023},
doi = {10.1007/978-3-031-42788-6_16}
}
Scanning Electron Microscopy (SEM) have found prosperous ground in the characterization of multiphase materials. One of the fastest modes of SEM with the ability of distinguish different phases is Back-Scattered Electron (BSE) imaging. As an imaging technique, however, the application of a segmentation method is required for the extraction of quantitative results. A very common segmentation technique is based on Gaussian Mixture Models algorithm. This algorithm is able to deconvolute the image histogram into different distributions attributed to different phases of the material. In this work a systematic study on the evaluation of GMM accuracy and an investigation of its limitation is conducted. Towards this investigation, a framework of synthetic BSE image histograms has been conducted for the control of parameters that correlate sample composition and image acquisition setting. The application of this framework is realized for the calculation of the impact of collective parameters of image histogram on the accuracy of GMM deconvolution. To this end some rules of thump are extracted for the guidance of SEM user on the prediction of GMM accuracy based on the inspection of image histogram only. These rule of thump can me summarized if one can distinguish the number of peaks in the histogram equal to the number of gaussian component taking part in GMM. If this is not the case, statistical moments, kurtosis and skewness, can be used in order to differentiate a histogram suitable for an accurate GMM deconvolution from non-suitable ones.
@article{MChatzigeorgiou_etal_JM_23,
author = {Manolis Chatzigeorgiou and Michalis Vrigkas and Margarita Beazi-Katsiotiand Marios Katsiotis and Nikos Boukos and Vassilios Constantoudis},
title = {Segmentation of SEM images of multiphase materials: When Gaussian mixture models are accurate?},
journal = {Journal of Microscopy},
volume = {289},
number = {1},
pages = {58--70},
month = {January},
year = {2023},
doi = {https://doi.org/10.1111/jmi.13150}
}
Augmented reality (AR) technologies are constantly developing in various fields of communication such as entertainment, education, information, and marketing and other fields such as industrial product design among others. This paper aims to present an integrated AR workflow for the labelling of wine products. The proposed wine label enhancement workflow may work as follows: The wine business comes up with the idea of creating an AR experience for its wine products, then an AR expert designs the AR experience, and develops the AR application. As a final step in the process, the application is distributed to the users with the use of various platforms and the experience can then be activated by pointing the camera of a mobile device to the bottle label. The AR content is then generated and displayed to the user who can interact with the digital product on a whole new level.
@article{MVrigkas_etal_JM_23,
author = {Michalis Vrigkas and Alexandros Kleftodimos and Georgios Lappas },
title = {An augmented reality workflow for creating ``live'' wine labels},
journal = {International Journal of Entertainment Technology and Management},
volume = {1},
number = {4},
pages = {311--327},
month = {January},
year = {2022},
doi = {10.1504/IJENTTM.2022.10054762}
}
Location-based AR games are becoming increasingly popular in education. With location-based AR games, learners can obtain knowledge by visiting places of educational value through informative digital content that is activated and displayed on their mobile devices when specific locations are reached. To create location-based AR games, there are several available authoring tools. Taleblazer and Metaverse Studio are two popular platforms that are used nowadays by many educators. This study aims to perform a comparative analysis between these platforms to provide educators interested in developing location-based AR experiences with all the information needed to make an informed decision on which platform to use. The analysis examines the designer environment and its available features, the end-user interface, the documentation that accompanies each platform, and third-party applications that are developed by these tools. Furthermore, two game prototypes have been developed to better understand the two platforms’ functionality.
@article{Kleftodimos_etal_JM_23,
author = {Alexandros Kleftodimos and Georgios Lappas and Michalis Vrigkas},
title = {Taleblazer vs Metaverse: A comparative analysis of the two platforms for building AR location-based educational experiences},
journal = {International Journal of Entertainment Technology and Management},
volume = {1},
number = {4},
pages = {290--310},
month = {January},
year = {2022},
doi = {10.1504/IJENTTM.2022.10054761}
}
Multiphase materials are encountered in several areas of science and technology. Their properties are determined by the fraction of the phases (material compounds) constituting the composite material. Therefore, the quantitative characterization of phase fractions is highly demanded and has been the subject of extensive studies. To this end, a widely used technique is the segmentation of top-down back-scattered electron SEM (BSE-SEM) images given that different phases are depicted with pixel collections of different luminosity. Gaussian mixture models (GMM) are one the most popular and easily implemented methods to segment the BSE-SEM images through the deconvolution of their histograms. However, the accuracy and the limitations of their application have not been fully investigated. The aim of this paper is to design a neural-network approach to fill this gap and provide a fast tool for the automatic evaluation of the accuracy of GMM predictions for all material phases based on the inspection of the measured SEM image histogram alone. The proposed tool facilitates the decision-making process of an SEM user concerning the optimum choice of a segmentation method.
@inproceedings{MChatzigeorgiou_etal_SETN_22,
author = {Manolis Chatzigeorgiou and Michalis Vrigkas and Nikos Boukos and Margarita Beazi-Katsioti and Marios Katsiotis and Vassilios Constantoudis},
title = {Machine learning evaluation of microscopy image segmentation methods: The case of Gaussian mixture models},
booktitle = {Proc. 12th Hellenic Conference on Artificial Intelligence},
address = {Corfu, Greece},
articleno = {59},
numpages = {4},
doi = {10.1145/3549737.3549800},
month = {September},
year = {2022},
series = {SETN '22}
}
The rapid spread of the COVID-19 pandemic, in early 2020, has radically changed the lives of people. In our daily routine, the use of a face (surgical) mask is necessary, especially in public places, to prevent the spread of this disease. Furthermore, in crowded indoor areas, the automated recognition of people wearing a mask is a requisite for the assurance of public health. In this direction, image processing techniques, in combination with deep learning, provide effective ways to deal with this problem. However, it is a common phenomenon that well-established datasets containing images of people wearing masks are not publicly available. To overcome this obstacle and to assist the research progress in this field, we present a publicly available annotated image database containing images of people with and without a mask on their faces, in different environments and situations. Moreover, we tested the performance of deep learning detectors in images and videos on this dataset. The training and the evaluation were performed on different versions of the YOLO network using Darknet, which is a state-of-the-art real-time object detection system. Finally, different experiments and evaluations were carried out for each version of YOLO, and the results for each detector are presented.
@article{MVrigkas_etal_22,
author = {Michalis Vrigkas and Evangelia-Andriana Kourfalidou and Marina E. Plissiti and Christophoros Nikou},
title = {FaceMask: A new image dataset for the automated identification of people wearing masks in the wild},
journal = {Sensors},
volume = {22},
number = {3},
article-number = {896},
month = {January},
year = {2022},
doi = {https://doi.org/10.3390/s22030896}
}
In this work, a supervised probabilistic approach is proposed that integrates the learning using privileged information (LUPI) paradigm into a hidden conditional random field (HCRF) model, called HCRF+, for human action recognition. The proposed model employs a self-training technique for automatic estimation of the regularization parameters of the objective function. Moreover, the method provides robustness to outliers by modeling the conditional distribution of the privileged information by a Student's t-density function, which is naturally integrated into the HCRF+ framework. The proposed method was evaluated using different forms of privileged information on four publicly available datasets. The experimental results demonstrate its effectiveness concerning the-state-of-the-art in the LUPI framework using both hand-crafted and deep learning-based features extracted from a convolutional neural network.
@article{MVrigkas_etal_21,
author = {Michalis Vrigkas and Evangelos Kazakos and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Human activity recognition using robust adaptive privileged probabilistic learning},
journal = {Pattern Analysis and Applications},
volume = {24},
number = {3},
pages = {915–-932},
month = {January},
year = {2021},
doi = {https://doi.org/10.1007/s10044-020-00953-x}
}
In this paper, we study the concepts, materials, tools, and applications that constitute what we call augmented reality (AR) for the wine industry. A comprehensive review of what are the basic multimedia content and the minimum algorithmic requirements used to implement successful AR applications for wine products is given. To this end, we provide a detailed analysis of how AR technology is used to create augmented “live” wine labels, and how digital storytelling has revolutionized wine products marketing. Also, we describe the use of AR technology to promote winemaking companies to influence consumer preferences. Finally, we report the characteristics of future research directions and some open issues and challenges on using AR for wine product promotion.
@inproceedings{MVrigkas_etal_ETLTC_21,
author = {Michalis Vrigkas and Georgios Lappas and Alexandros Kleftodimos and Amalia Triantafillidou},
title = {Augmented Reality for Wine Industry: Past, Present, and Future},
booktitle = {3rd International Conference on Information and Communications Technology},
address = {Aizuwakamatsu Japan},
pages = {04006},
month = {January},
year = {2021},
doi = {10.1051/shsconf/202110204006}
}
In this paper, the task of gender and age recognition is performed on pedestrian still images, which are usually captured in-the-wild with no near face-frontal information. Moreover, another difficulty originates from the underlying class imbalance in real examples, especially for the age estimation problem. The scope of the paper is to examine how different loss functions in convolutional neural networks (CNN) perform under the class imbalance problem. For this purpose, as a backbone, we employ the Residual Network (ResNet). On top of that, we attempt to benefit from appearance-based attributes, which are inherently present in the available data. We incorporate this knowledge in an autoencoder, which we attach to our baseline CNN for the combined model to jointly learn the features and increase the classification accuracy. Finally, all of our experiments are evaluated on two publicly available datasets.
@inproceedings{GChatzitzisi_etal_20,
author = {Georgia Chatzitzisi and Michalis Vrigkas and Christophoros Nikou},
title = {Gender and age estimation without facial information from still images},
booktitle = {International Symposioum on Visual Computing},
publisher = {Springer International Publishing},
address = {San Diego, CA},
pages = {488-500},
month = {October},
year = {2020},
isbn = {978-3-030-64556-4}
}
Advanced methodologies for transmitting compressed images, within acceptable ranges of transmission rate and loss of information, make it possible to transmit a medical image through a communication channel. Most prior works on 3D medical image compression consider volumetric images as a whole but fail to account for the spatial and temporal coherence of adjacent slices. In this paper, we set out to develop a 3D medical image compression method that extends the 3D wavelet difference reduction algorithm by computing the similarity of the pixels in adjacent slices and progressively compress only the similar slices. The proposed method achieves high-efficiency performance on publicly available datasets of MRI scans by achieving compression down to one bit per voxel with PSNR and SSIM up to 52.3 dB and 0.7578, respectively.
@inproceedings{MZerva_etal_20,
author = {Matina Ch. Zerva and Michalis Vrigkas and Lisimachos P. Kondi and Christophoros Nikou},
title = {Improving {3D} medical image compression efficiency using spatiotemporal coherence},
booktitle = {Proc. IS&T International Symposioum on Electronic Imaging, Image Processing: Algorithms and Systems XVII},
pages = {63-1-63-6},
address = {Burlingame, CA},
month = {January},
year = {2020}
}
Many approaches for action recognition focus on general actions, such as “running” or “walking”. This work presents a method for recognizing carrying actions in single images, by utilizing privileged information, such as annotations, available only during training, following the learning using privileged information paradigm. In addition, we introduce a dataset for carrying actions, formed using images extracted from YouTube videos depicting several scenarios. We accompany the dataset with a variety of different annotation types that include human pose, object and scene attributes. The experimental results demonstrate that our method, boosted sample averaged F1 score performance by 15.4% and 4.15% respectively, in the validation and testing partitions of our dataset, when compared to an end-to-end CNN model, trained only with observable information.
@inproceedings{CSmailis_ICIP19,
author = {Christos Smailis and Michalis Vrigkas and Ioannis A. Kakadiaris},
title = {RECASPIA: Recognizing carrying actions in single images using privileged information},
booktitle = {Proc. 26th IEEE International Conference on Image Processing},
pages = {26--30},
address = {Taipei, Taiwan},
month = {September},
year = {2019}
}
Hidden conditional random fields (HCRFs) are a powerful supervised classification system, which is able to capture the intrinsic motion patterns of a human action. However, finding the optimal number of hidden states remains a severe limitation for this model. This paper addresses this limitation by proposing a new model, called robust incremental hidden conditional random field (RI-HCRF). A hidden Markov model (HMM) is created for each observation paired with an action label and its parameters are defined by the potentials of the original HCRF graph. Starting from an initial number of hidden states and increasing their number incrementally, the Viterbi path is computed for each HMM. The method seeks for a sequence of hidden states, where each variable participates in a maximum number of optimal paths. Thereby, variables with low participation in optimal paths are rejected. In addition, a robust mixture of Student's t-distributions is imposed as a regularizer to the parameters of the model. The experimental results on human action recognition show that RI-HCRF successfully estimates the number of hidden states and outperforms all state-of-the-art models.
@inproceedings{MVrigkas_ISVC18,
author = {Michalis Vrigkas and Ermioni Mastora and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Robust incremental hidden conditional random fields for human action recognition},
booktitle = {Proc. 13th International Symposium on Visual Computing},
address = {Las Vegas, NV},
month = {November},
pages = {126--136},
year = {2018}
}
Background
Studies have demonstrated that the current US guidelines based on American College of Cardiology/American Heart Association (ACC/AHA) Pooled Cohort Equations Risk Calculator may underestimate risk of atherosclerotic cardiovascular disease (CVD) in certain high‐risk individuals, therefore missing opportunities for intensive therapy and preventing CVD events. Similarly, the guidelines may overestimate risk in low risk populations resulting in unnecessary statin therapy. We used Machine Learning (ML) to tackle this problem.
Methods and Results
We developed a ML Risk Calculator based on Support Vector Machines (SVMs) using a 13‐year follow up data set from MESA (the Multi‐Ethnic Study of Atherosclerosis) of 6459 participants who were atherosclerotic CVD‐free at baseline. We provided identical input to both risk calculators and compared their performance. We then used the FLEMENGHO study (the Flemish Study of Environment, Genes and Health Outcomes) to validate the model in an external cohort. ACC/AHA Risk Calculator, based on 7.5% 10‐year risk threshold, recommended statin to 46.0%. Despite this high proportion, 23.8% of the 480 “Hard CVD” events occurred in those not recommended statin, resulting in sensitivity 0.76, specificity 0.56, and AUC 0.71. In contrast, ML Risk Calculator recommended only 11.4% to take statin, and only 14.4% of “Hard CVD” events occurred in those not recommended statin, resulting in sensitivity 0.86, specificity 0.95, and AUC 0.92. Similar results were found for prediction of “All CVD” events.
Conclusions
The ML Risk Calculator outperformed the ACC/AHA Risk Calculator by recommending less drug therapy, yet missing fewer events. Additional studies are underway to validate the ML model in other cohorts and to explore its ability in short‐term CVD risk prediction.
@article{Kakadiaris_JAHA18,
author = {Ioannis A. Kakadiaris and Michalis Vrigkas and Albert A. Yen and Tatiana Kuznetsova and Matthew Budoff and Morteza Naghavi},
title = {Machine learning outperforms {ACC/AHA CVD} risk calculator in {MESA}},
journal = {Journal of the American Heart Association},
volume = {7},
number = {22},
pages = {e009476},
year = {2018},
month = {November},
doi = {10.1161/JAHA.118.009476}
}
Introduction: Machine learning (ML) is poised to revolutionize healthcare. Current national guidelines for prediction and prevention of atherosclerotic cardiovascular disease (ASCVD) use ACC/AHA Pooled Cohort Equation Risk Calculator which relies on traditional risk factors and linear statistical models. Unfortunately, this approach yields a low level of sensitivity and specificity. The low sensitivity results in missing high-risk individuals who need intensive therapy and the low specificity results in millions of people unnecessarily recommended drugs such as statin. We aimed to utilize Machine Learning (ML) to create a more accurate predictor of ASCVD events and whom to recommend statin.
Methods: We developed and validated a ML Risk Calculator based on Support Vector Machines (SVMs) using the latest 13-year follow up dataset from MESA (Multi-Ethnic Study of Atherosclerosis) of 6,459 participants who were free of cardiovascular disease at baseline. We provided identical input to the ACC/AHA and ML risk calculators and compared their accuracy. We also validated the ML model in another longitudinal cohort: the Flemish Study on Environment, Genes and Health Outcomes (FLEMENGHO).
Results: According to the ACC/AHA Risk Calculator and a 7.5% 10-year risk threshold, 46.0% would be recommended statin. Despite this high proportion, 23.8% of the 480 “Hard CVD” events occurred in those not recommended statin, resulting in sensitivity (Sn) 0.76, specificity (Sp) 0.56, and AUC 0.71. In contrast, ML Risk Calculator recommended statin to 11.4%, and only 14.4% of “Hard CVD” events occurred in those not recommended statin, resulting in Sn 0.86, Sp 0.95, and AUC 0.92. Similar results were seen in prediction of “All CVD” events.
Conclusions: The ML Risk Calculator outperformed the ACC/AHA Risk Calculator by recommending less drug therapy, yet missing fewer events. Additional studies are underway to validate the ML model in other cohorts and to explore its ability in predicting short-term (1-5 years) events with additional biomarkers including imaging. Machine learning is paving the way for early detection of asymptomatic high-risk individuals destined to a CVD event in the near future, the Vulnerable Patient.
@inproceedings{Kakadiaris_etal18,
author = {Ioannis A Kakadiaris and Michail Vrigkas and Albert Yen and Tatiana Kuznetsova and Matthew Budoff and Morteza Naghavi},
title = {Machine learning outperforms ACC/AHA CVD risk calculator in MESA offering new opportunities for short-term risk prediction and early detection of the vulnerable patient},
journal = {Circulation},
volume = {138},
number = {Suppl\ 1},
pages = {A17154--A17154},
year = {2018},
month = {November},
address = {Chicago, IL},
publisher = {American Heart Association, Inc.},
doi = {10.1161/circ.138.suppl\_1.17154}
}
An algorithm for the localization and counting of cells in histopathological images is presented. The algorithm relies on the presegmentation of an image into a number of superpixels followed by two random forests for classification. The first random forest determines if there are any cells in the superpixels at its input and the second random forest provides the number of cells in the respective superpixel. The algorithm is evaluated on a bone marrow histopathological dataset. We argue that a single random forest is not sufficient to detect all the cells in the image while a cascade of classifiers achieves higher accuracy. The results compare favorably with the state of the art but with a lower computational cost.
@inproceedings{MOman_VISAPP18,
author = {Oman Maga\~{n}a-Tellez and Michalis Vrigkas and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {SPICE: Superpixel classification for cell detection and counting},
booktitle = {Proc. 13th International Conference on Computer Vision Theory and Applications},
address = {Funchal, Madeira, Portugal},
month = {January},
pages = {485--490},
year = {2018}
}
Background: Studies have shown that the status quo for atherosclerotic cardiovascular disease (ASCVD) prediction in the U.S. - using ACC/AHA Pooled Cohort Equations Risk Calculator - is inaccurate and results in overtreatment of low-risk and undertreatment of high-risk individuals. Machine Learning (ML) is poised to revolutionize healthcare. We used ML to develop a new ASCVD risk calculator and tackled the problem.
Methods: We developed a ML Risk Calculator using the latest 13-year follow up dataset from MESA (Multi-Ethnic Study of Atherosclerosis) of 6,814 participants who were free of clinical CVD at baseline. We gave identical input to both calculators and compared their accuracy for recommending statin to 5,415 subjects (age 60.6 ± 9.7 years; 47.3% males) who were not on lipid lowering treatment at baseline.
Results: Over 13 years, 775 (14.3%) “All CVD” and 381 (7.0%) “Hard CVD” events occurred. According to ACC/AHA Risk Calculator and a 7.5% 10-year risk threshold for treatment, 42.9% would be recommended to take statin. Despite the high proportion recommended for statin treatment, 25.7% of “Hard CVD” and 26.3% of “All CVD” events occurred in those not recommended statin, resulting in sensitivity (Sn) 0.74, specificity (Sp) 0.60, and AUC 0.72 for “Hard CVD” and Sn 0.73, Sp 0.62, and AUC 0.73 for “All CVD”. In sharp contrast, the ML Risk Calculator recommended only 10.6% to take statin, and only 15.0% of “Hard CVD” and 4.9% of “All CVD” events occurred in those not recommended statin, resulting in Sn 0.84, Sp 0.95, and AUC 0.92 for “Hard CVD” and Sn 0.95, Sp 0.88, and AUC 0.95 for “All CVD”.
Conclusions: ML clearly outperformed the ACC/AHA Risk Calculator by recommending less drug therapy and missing fewer events. Further studies are underway to validate these findings in other cohorts. As we introduce our ML model to more data particularly to cases in which events occurred weeks or months following data collection instead of years, short-term risk prediction may be possible.
@article{IKakadiaris_AHA17,
author = {Ioannis Kakadiaris and Michalis Vrigkas and Matthew Budoff and Albert Yen and Morteza Naghavi},
title = {Machine learning outperformed {ACC/AHA} {P}ooled {C}ohort {E}quations {R}isk {C}alculator for detection of high-risk asymptomatic individuals and recommending treatment for prevention of cardiovascular events in the {M}ulti-{E}thnic {S}tudy of {A}therosclerosis {(MESA)}},
volume = {136},
number = {Suppl 1},
pages = {A23075--A23075},
year = {2017},
month = {November 11-15},
address = {Anaheim, CA},
publisher = {American Heart Association, Inc.},
issn = {0009-7322},
URL = {http://circ.ahajournals.org/content/136/Suppl_1/A23075},
eprint = {http://circ.ahajournals.org/content},
journal = {Circulation}
}
Classification models may often suffer from “structure imbalance” between training and testing data that may occur due to the deficient data collection process. This imbalance can be represented by the learning using privileged information (LUPI) paradigm. In this paper, we present a supervised probabilistic classification approach that integrates LUPI into a hidden conditional random field (HCRF) model. The proposed model is called LUPI-HCRF and is able to cope with additional information that is only available during training. Moreover, the proposed method employes Student's
@inproceedings{MVrigkas_ICCVW17,
author = {Michalis Vrigkas and Evangelos Kazakos and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Inferring human activities using robust privileged probabilistic learning},
booktitle = {Proc. IEEE International Conference on Computer Vision Workshops},
year = {2017},
month = {October},
pages = {2658--2665},
address = {Venice, Italy}
}
Incorporating additional knowledge in the learning process can be beneficial for several computer vision and machine learning tasks. Whether privileged information originates from a source domain that is adapted to a target domain, or as additional features available at training time only, using such privileged (i.e., auxiliary) information is of high importance as it improves the recognition performance and generalization. However, both primary and privileged information are rarely derived from the same distribution, which poses an additional challenge to the recognition task. To address these challenges, we present a novel learning paradigm that leverages privileged information in a domain adaptation setup to perform visual recognition tasks. The proposed framework, named Adaptive SVM+, combines the advantages of both the learning using privileged information (LUPI) paradigm and the domain adaptation framework, which are naturally embedded in the objective function of a regular SVM. We demonstrate the effectiveness of our approach on the publicly available Animals with Attributes and INTERACT datasets and report state-of-the-art results in both of them.
@inproceedings{NSarafianos_ICCVW17,
author = {Nikolaos Sarafianos and Michalis Vrigkas and Ioannis A. Kakadiaris},
title = {Adaptive SVM+: Learning with privileged information for domain adaptation},
booktitle = {Proc. IEEE International Conference on Computer Vision Workshops},
year = {2017},
month = {October},
pages = {2637--2644},
address = {Venice, Italy}
}
In this paper, a human behavior recognition method using multimodal features is presented. We focus on modeling individual and social behaviors of a subject (e.g., friendly/aggressive or hugging/kissing behaviors) with a hidden conditional random field (HCRF) in a supervised framework. Each video is represented by a vector of spatio-temporal visual features (STIP, head orientation and proxemic features) along with audio features (MFCCs). We propose a feature pruning method for removing irrelevant and redundant features based on the spatio-temporal neighborhood of each feature in a video sequence. The proposed framework assumes that human movements are highly correlated with sound emissions. For this reason, canonical correlation analysis (CCA) is employed to find correlation between the audio and video features prior to fusion. The experimental results, performed in two human behavior recognition datasets including political speeches and human interactions from TV shows, attest the advantages of the proposed method compared with several baseline and alternative human behavior recognition methods.
@article{MVrigkas_TAffC15,
author = {Michalis Vrigkas and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Identifying human behaviors using synchronized audio-visual cues},
journal = {IEEE Transactions on Affective Computing},
year = {2017},
volume = {8},
number = {1},
pages = {54-66},
doi = {10.1109/TAFFC.2015.2507168},
month = {January}
}
This thesis solves the problem of human activity recognition from video sequences. To model human activities, conditional random fields were applied using data from heterogeneous sources. Moreover, a novel classification scheme that is based on the learning using privileged information (LUPI) paradigm was also proposed, where privileged information is given as an additional input to the classification model and it is available only during training but never during testing. Experimental results demonstrated that privileged information helps to build a stronger classifier than one would not learn without it, while it significantly increases the recognition accuracy of the model.
@phdthesis{phdthesisMVrigkas16,
author = {Michalis Vrigkas},
title = {Human activity recognition using conditional random fields and privileged information},
school = {Department of Computer Science and Engineering, University of Ioannina},
year = {2018},
month = {May}
}
In many human activity recognition systems the size of the unlabeled training data may be significantly large due to expensive human effort required for data annotation. Moreover, the insufficient data collection process from heterogenous sources may cause dissimilarities between training and testing data. To address these limitations, a novel probabilistic approach that combines learning using privileged information (LUPI) and active learning is proposed. A pool-based privileged active learning approach is presented for semi-supervising learning of human activities from multimodal labeled and unlabeled data. Both uncertainty and distance from the decision boundary are used as a query inference strategies for selecting an unlabeled observation and query its label. Experimental results in four publicly available datasets demonstrate that the proposed method can identify with high accuracy complex human activities.
@inproceedings{MVrigkas_ICIP16,
author = {Michalis Vrigkas and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Active privileged learning of human activities from weakly labeled samples},
booktitle = {Proc. 23rd IEEE International Conference on Image Processing},
year = {2016},
month = {September},
pages = {3036--3040},
address = {Phoenix, AZ}
}
Most of the facial expression recognition methods consider that both training and testing data are equally distributed. As facial image sequences may contain information for heterogeneous sources, facial data may be asymmetrically distributed between training and testing, as it may be difficult to maintain the same quality and quantity of information. In this work, we present a novel classification method based on the learning using privileged information (LUPI) paradigm to address the problem of facial expression recognition. We introduce a probabilistic classification approach based on conditional random fields (CRFs) to indirectly propagate knowledge from privileged to regular feature space. Each feature space owns specific parameter settings, which are combined together through a Gaussian prior, to train the proposed t-CRF+ model and allow the different tasks to share parameters and improve classification performance. The proposed method is validated on two challenging and publicly available benchmarks on facial expression recognition and improved the state-of-the-art methods in the LUPI framework.
@inproceedings{MVrigkas_ICIP16,
author = {Michalis Vrigkas and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Exploiting privileged information for facial expression recognition},
booktitle = {Proc. 9th IAPR/IEEE International Conference on Biometrics},
year = {2016},
month = {June},
pages = {1--8},
address = {Halmstad, Sweden},
doi = {10.1109/ICB.2016.7550048},
note = {Honorable Mention Paper Award}
}
Recognizing human activities from video sequences or still images is a challenging task due to problems, such as background clutter, partial occlusion, changes in scale, viewpoint, lighting, and appearance. Many applications, including video surveillance systems, human-computer interaction, and robotics for human behavior characterization, require a multiple activity recognition system. In this work, we provide a detailed review of recent and state-of-the-art research advances in the field of human activity classification. We propose a categorization of human activity methodologies and discuss their advantages and limitations. In particular, we divide human activity classification methods into two large categories according to whether they use data from different modalities or not. Then, each of these categories is further analyzed into sub-categories, which reflect how they model human activities and what type of activities they are interested in. Moreover, we provide a comprehensive analysis of the existing, publicly available human activity classification datasets and examine the requirements for an ideal human activity recognition dataset. Finally, we report the characteristics of future research directions and present some open issues on human activity recognition.
@article{MVrigkas_FRONTIERS2015,
author = {Michalis Vrigkas and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {A review of human activity recognition methods},
journal = {Frontiers in Robotics and Artificieal Inteligence},
volume = {2},
number = {28},
pages = {1--26},
year = {2015},
url = {http://www.frontiersin.org/vision_systems_theory,_tools_and_applications/10.3389/frobt.2015.00028/abstract},
doi = {10.3389/frobt.2015.00028},
issn = {2296-9144}
}
The automated interpretation of Pap smear images is a challenging issue with several aspects. The accurate segmentation of the structuring elements of each cell is a crucial procedure which entails in the correct identification of pathological situations. However, the extended cell overlapping in Pap smear slides complicates the automated analysis of these cytological images. In this work, we propose an efficient algorithm for the separation of the cytoplasm area of overlapping cells. The proposed method is based on the fact that in isolated cells the pixels of the cytoplasm exhibit similar features and the cytoplasm area is homogeneous. Thus, the observation of intensity changes in extended subareas of the cytoplasm indicates the existence of overlapping cells. In the first step of the proposed method, the image is tesselated into perceptually meaningful individual regions using a superpixel algorithm. In a second step, these areas are merged into regions exhibiting the same characteristics, resulting in the identification of each cytoplasm area and the corresponding nuclei. The area of overlap is then detected using an algorithm that specifies faint changes in the intensity of the cytoplasm of each cell. The method has been evaluated on cytological images of conventional Pap smears, and the results are very promising.
@inproceedings{MPlissiti_IWSSIP15,
author = {Marina E. Plissiti and Michalis Vrigkas and Christophoros Nikou},
title = {Segmentation of cell clusters in Pap smear images using intensity variation between superpixels},
booktitle = {Proc. 22nd International Conference on Systems, Signals and Image Processing},
year = {2015},
month = {September},
pages = {184--187},
address = {London, UK}
}
A global robust M-estimation scheme for maximum a posteriori (MAP) image super-resolution which efficiently addresses the presence of outliers in the low-resolution images is proposed. In iterative MAP image super-resolution, the objective function to be minimized involves the highly resolved image, a parameter controlling the step size of the iterative algorithm, and a parameter weighing the data fidelity term with respect to the smoothness term. Apart from the robust estimation of the high-resolution image, the contribution of the proposed method is twofold: (1) the robust computation of the regularization parameters controlling the relative strength of the prior with respect to the data fidelity term and (2) the robust estimation of the optimal step size in the update of the high-resolution image. Experimental results demonstrate that integrating these estimations into a robust framework leads to significant improvement in the accuracy of the high-resolution image.
@article{MVrigkas_JEI14,
author = {Michalis Vrigkas and Christophoros Nikou and Lisimachos P. Kondi},
title = {Robust maximum a posteriori image super-resolution},
journal = {Journal of Electronic Imaging},
volume = {23},
number = {4},
pages = {043016},
year = {2014},
isbn = {1017-9909},
doi = {10.1117/1.JEI.23.4.043016},
URL = {http://dx.doi.org/10.1117/1.JEI.23.4.043016}
}
A human behavior recognition method with an application to political speech videos is presented. We focus on modeling the behavior of a subject with a conditional random field (CRF). The unary terms of the CRF employ spatiotemporal features (i.e., HOG3D, STIP and LBP). The pairwise terms are based on kinematic features such as the velocity and the acceleration of the subject. As an exact solution to the maximization of the posterior probability of the labels is generally intractable, loopy belief propagation was employed as an approximate inference method. To evaluate the performance of the model, we also introduce a novel behavior dataset, which includes low resolution video sequences depicting different people speaking in the Greek parliament. The subjects of the Parliament dataset are labeled as friendly, aggressive or neutral depending on the intensity of their political speech. The discrimination between friendly and aggressive labels is not straightforward in political speeches as the subjects perform similar movements in both cases. Experimental results show that the model can reach high accuracy in this relatively difficult dataset.
@inproceedings{MVrigkas_SETN14,
author = {Michalis Vrigkas and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Classifying behavioral attributes using conditional random fields},
booktitle = {Proc. 8th Hellenic Conference on Artificial Intelligence},
year = {2014},
month = {May},
pages = {95--104},
volume = {8445},
series = {Lecture Notes in Computer Science},
address = {Ioannina, Greece}
}
A learning-based framework for action representation and recognition relying on the description of an action by time series of optical flow motion features is presented. In the learning step, the motion curves representing each action are clustered using Gaussian mixture modeling (GMM). In the recognition step, the optical flow curves of a probe sequence are also clustered using a GMM, then each probe sequence is projected onto the training space and the probe curves are matched to the learned curves using a non-metric similarity function based on the longest common subsequence, which is robust to noise and provides an intuitive notion of similarity between curves. Alignment between the mean curves is performed using canonical time warping. Finally, the probe sequence is categorized to the learned action with the maximum similarity using a nearest neighbor classification scheme. We also present a variant of the method where the length of the time series is reduced by dimensionality reduction in both training and test phases, in order to smooth out the outliers, which are common in these type of sequences. Experimental results on KTH, UCF Sports and UCF YouTube action databases demonstrate the effectiveness of the proposed method.
@article{MVrigkas_CVIU14,
author = {Michalis Vrigkas and Vasileios Karavasilis and Christophoros Nikou and Ioannis A. Kakadiaris},
title = {Matching mixtures of curves for human action recognition},
journal = {Computer Vision and Image Understanding},
volume = {119},
pages = {27--40},
year = {2014},
issn = {1077--3142},
doi = {http://dx.doi.org/10.1016/j.cviu.2013.11.007}
}
The accuracy of image registration plays a dominant role in image super-resolution methods and in the related literature, landmark-based registration methods have gained increasing acceptance in this framework. In this work, we take advantage of a maximum a posteriori (MAP) scheme for image super-resolution in conjunction with the maximization of mutual information to improve image registration for super-resolution imaging. Local as well as global motion in the low-resolution images is considered. The overall scheme consists of two steps. At first, the low-resolution images are registered by establishing correspondences between image features. The second step is to fine-tune the registration parameters along with the high-resolution image estimation, using the maximization of mutual information criterion. Quantitative and qualitative results are reported indicating the effectiveness of the proposed scheme, which is evaluated with different image features and MAP image super-resolution computation methods.
@article{MVrigkas_SPIC13,
author = {Michalis Vrigkas and Christophoros Nikou and Lisimachos P. Kondi},
title = {Accurate image registration for \{MAP\} image super-resolution},
journal = {Signal Processing: Image Communication},
volume = {28},
number = {5},
pages = {494--508},
year = {2013},
issn = {0923-5965},
doi = {10.1016/j.image.2012.12.008}
}
A framework for action representation and recognition based on the description of an action by time series of optical flow motion features is presented. In the learning step, the motion curves representing each action are clustered using Gaussian mixture modeling (GMM). In the recognition step, the optical flow curves of a probe sequence are also clustered using a GMM and the probe curves are matched to the learned curves using a non-metric similarity function based on the longest common subsequence which is robust to noise and provides an intuitive notion of similarity between trajectories. Finally, the probe sequence is categorized to the learned action with the maximum similarity using a nearest neighbor classification scheme. Experimental results on common action databases demonstrate the effectiveness of the proposed method.
@inproceedings{MVrigkas_VISAPP13,
author = {Michalis Vrigkas and Vasileios Karavasilis and Christophoros Nikou and Ioannis Kakadiaris},
title = {Action recognition by matching clustered trajectories of motion vectors},
booktitle = {Proc. 8th International Conference on Computer Vision Theory and Applications},
year = {2013},
pages = {112--117},
address = {Barcelona, Spain},
month = {February}
}
In this work, we propose an adaptive M-estimation scheme for robust image super-resolution. The proposed algorithm relies on a maximum a posteriori (MAP) framework and addresses the presence of outliers in the low resolution images. Moreover, apart from the robust estimation of the high resolution image, the contribution of the method is twofold: (i) the robust computation of the regularization parameters controlling the relative strength of the prior with respect to the data fidelity term and (ii) the robust estimation of the optimal step size in the update of the high resolution image. Experimental results demonstrate that integrating these estimations into a robust framework leads to significant improvement in the accuracy of the high resolution image.
@inproceedings{MVrigkas_ICIP12,
author = {Michalis Vrigkas and Christophoros Nikou and Lisimachos P. Kondi},
title = {A fully robust framework for MAP image Super-Resolution},
booktitle = {Proc. IEEE International Conference on Image Processing},
year = {2012},
pages = {2225--2228},
address = {Orlando, FL},
month = {September}
}
Accurate image registration plays a preponderant role in image super-resolution methods and in the related literature landmarkbased registration methods have gained increasing acceptance in this framework. However, their solution relies on point correspondences and on least squares estimation of the registration parameters necessitating further improvement. In this work, a maximum a posteriori scheme for image super-resolution is presented where the image registration part is accomplished in two steps. At first, the lowresolution images are registered by establishing correspondences between robust SIFT features. In the second step, the estimation of the registration parameters is fine-tuned along with the estimation of the high resolution image, in an iterative scheme, using the maximization of the mutual information criterion. Numerical results showed that the reconstructed image is consistently of higher quality than in standard MAP-based methods employing only landmarks.
@inproceedings{MVrigkas_ICASSP11,
author = {Michalis Vrigkas and Christophoros Nikou and Lisimachos P. Kondi},
title = {On the improvement of image registration for high accuracy super-resolution},
booktitle = {Proc. IEEE International Conference on Acoustics, Speech and Signal Processing},
year = {2011},
pages = {981--984},
address = {Prague, Czech Republic},
month = {May}
}
This thesis addresses the problem of image super-resolution. We use the term super-resolution to describe the process of obtaining a high-resolution image from a set of shifted, rotated, and degraded by noise low-resolution images. This procedure also involves the estimation of the registration parameters between the images. In the method presented here, the registration parameters between the low-resolution images are updated along with the high-resolution image in a iterative coordinate-descent optimization procedure. We describe a method for extracting distinctive invariant features from low-resolution images that can be used to perform a reliable matching between the low-resolution images in the least squares sense. In the second part of this dissertation, we propose a method of image super-resolution where the estimation of the registration parameters is fine tuned by the maximization of the mutual information registration criterion. The experimental results demonstrate that the proposed method yields sub-pixel registration accuracy and better quality of the reconstructed high-resolution image. Our method uses robust M-estimators for computing the difference between the high-resolution estimate and each low-resolution frame. The experimental results con firm the effectiveness of our method by suppressing the outliers and demonstrate the superior performance over other robust image super-resolution algorithms.
@phdthesis{mscthesisMVrigkas10,
author = {Michalis Vrigkas},
title = {Image super-resolution methods},
school = {Department of Computer Science, University of Ioannina},
year = {2010},
month = {October}
}
A technique for filling in areas with missing data in both black and white and color images is presented here. Image inpainting is the technique of modifying an image in an undetectable way. After the users select the area they want to restore, the algorithm automatically fills the area with the information that surrounds it. This technique, in contrast to previous approaches, does not require the user to determine where the information comes from. This is done automatically and it allows for the simultaneous inpainting of numerous areas, which include completely different structures and backgrounds. In addition, no restriction is required on the topology of the areas that we may inpaint. Applications of this technique include restoring old photos and damaged film, removing text such as dates, subtitles, or advertising, and removing objects such as microphones or wires. The second part of this thesis is about Poisson image processing. Using general interpolation mechanisms based on solving Poisson equations, a variety of new tools are presented for seamless image processing. The technique involves the seamless addition of both transparent and opaque objects.
@phdthesis{bscthesisMVrigkas08,
author = {Michalis Vrigkas},
title = {Image inpainting by partial differential equations},
school = {Department of Computer Science, University of Ioannina},
year = {2008},
month = {October}
}
I am actively involved in learning efficient and discriminative image representations and provide solutions to challenging real-world problems. My research is focused on Computer Vision, Image and Video Processing, Machine Learning, and Augmented Reality. Special areas of research such as Biometrics, Medical Image Analysis, and Predictive Analytics for heart attack prediction have also attracted my interest. My research is focused on challenging tasks with a significant societal impact and is related to developing machine learning algorithms for real-world applications such as medical and biometric applications.
Each of the application areas described above employs a range of computer vision tasks; more or less well-defined measurement or processing problems, which can be solved using a variety of methods. I approach these problems with methods from signal processing and applied mathematics. I have worked on several research projects and C/C++, MATLAB, and Python are the languages I prefer to use for code developing.
The DEVIATE project (Deep Embedding of Visual Information for Demographic Consumer Analytics and Targeted Engagement at Scale) represents a pioneering initiative for the digital transformation of retail, aiming to develop an integrated computer vision platform for analyzing consumer behavior in real-world environments.
Through the utilization of advanced Computer Vision and Deep Machine Learning algorithms, the platform achieves visual tracking of multiple consumers simultaneously, accurate estimation of key demographic characteristics —such as gender and age group— as well as detailed recording of customer interaction with shelves and products.
The key innovation of DEVIATE lies in the "deep embedding" of visual information, which allows for the combined analysis of detection, tracking, and demographic data in a single, functional system. Unlike laboratory applications, the project is designed to meet the challenges of industrial scale.
The ultimate goal of DEVIATE is to offer businesses the necessary tools for data-driven decision-making, improving customer experience and enhancing targeted commercial communication through scientifically grounded understanding of the consumer journey.
Below you may find a list of some codes or resources I contribute to the research community. All datasets are publicly available for research purposes only.
© Copyright Notice: This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. These works may not be reposted without the explicit permission of the copyright holder. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright and/or copyright holders. All statements of fact, opinion or conclusions contained herein are those of the authors and should not be construed as representing the official views or policies of the sponsors. In most cases, these works may not be reposted without the explicit permission of the copyright holders. Please contact authors for further details.
The FaceMask Database consists of 4,866 images of people in diffrerent environments and situations. These images were manually collected from Google Images and annotated with LabelImg tool in YOLO format. They are divided into two categories containing people wearing face masks and people not wearing face masks. The Dataset is splited into 3 folders -the training folder, the validation folder, and the test folder.
If you use this dataset, I would be grateful if you cite with one of the following related publications:
The Parliament dataset is a collection of 228 video sequences, depicting political speeches in the Greek parliament, at a resolution of 320 × 240 pixels at 25 fps. All behaviors were recorded for 20 different subjects. The videos were acquired with a static camera and contain uncluttered backgrounds. The length of the video sequences is 250 frames. The video sequences were manually labeled with one of three behavioral labels: friendly (90 videos), aggressive (73 videos), or neutral (65 videos). The subjects express their opinion on a specific law proposal and they adjust their body movements and voice intensity level according to whether they agree with that or not.
The dataset was annotated by two observers of Greek origin, who watched the videos independently and recorded their labels separately. Disagreement was resolved by a third observer. The observers were asked to categorize the videos with respect to the notions of kindness and aggressiveness according to a general perception of a political speech by a citizen with a Greek mentality as follows. (i) Subjects with large and abrupt body, head and hand movements and high speech signal amplitude are to be labeled as aggressive. This corresponds to statesmen who express strongly their disagreement with the topic discussed or a previous speech given by a political opponent. (ii) Subjects with very small variations in their motion and speech signal amplitude are to be labeled as neutral. This class includes standard political speeches only expressing a point of view without any strong indication (body motion or voice tone) of agreement or disagreement with the topic discussed. (iii) Subjects with large but smooth variations in the pose of their body and hands speaking with a normal speech signal amplitudes are to be labeled as friendly.
If you use this dataset, I would be grateful if you cite with one of the following related publications:
I would be happy to talk to you if you need my assistance in your research or you have any suggestions or comments about my work.
You can find me at my office located at University of Western Macedonia, Fourka Area, Kastoria, Greece.
Coordinates: 40.504973, 21.248093
University of Western Macedonia,
Department of Communication and Digital Media,
Fourka Area,
GR 52100, Kastoria,
Greece.


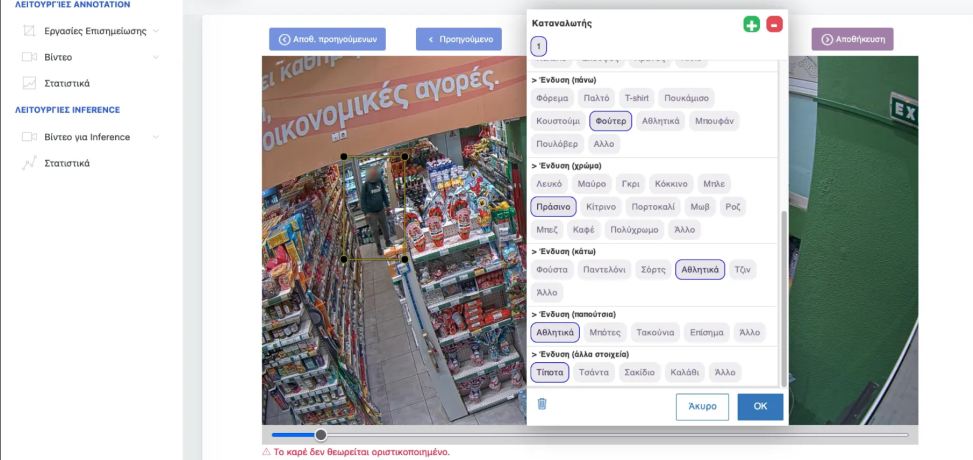{kind=link}
{kind=link}
{kind=link}